

volatile是JVM提供的轻量级的同步机制
保证可见性
不保证原子性
禁止指令重排(保证有序性)
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步的规定:
线程解锁前,必须把共享变量的值刷新回主内存
线程加锁前,必须读取主内存的最新值到自己的工作内存
加锁解锁是同一把锁
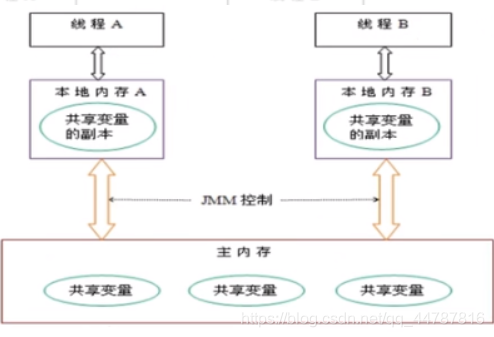
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:
可见性
通过前面对JMM的介绍,我们知道各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后再写回到主内存中的。
这就可能存在一个线程AAA修改了共享变量X的值但还未写回主内存时,另外一个线程BBB又对主内存中同一个共享变量X进行操作,但此时A线程工作内存中共享变量x对线程B来说并不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题
结果
即使线程AAA修改了变量写回了内存,但是主线程工作空间中,变量值一直是0 无法退出,因为线程间变量的修改是不可见的,没有通知主线程,内存中的共享变量发生了改变。
因此,需要有一种机制,能够是线程间能够相互看到共享变量。
使用volatile。轻量级锁。使得共享资源可以相互可见。
原子性指的是什么意思?
不可分割,完整性,也即某个线程正在做某个具体业务时,中间不可以被加塞或者被分割。需要整体完整要么同时成功,要么同时失败。
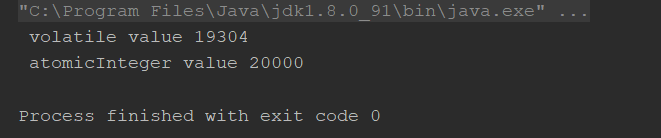
volatile不保证原子性案例演示:
number++在多线程下是非线程安全的。
我们可以将代码编译成字节码,可看出number++被编译成3条指令。
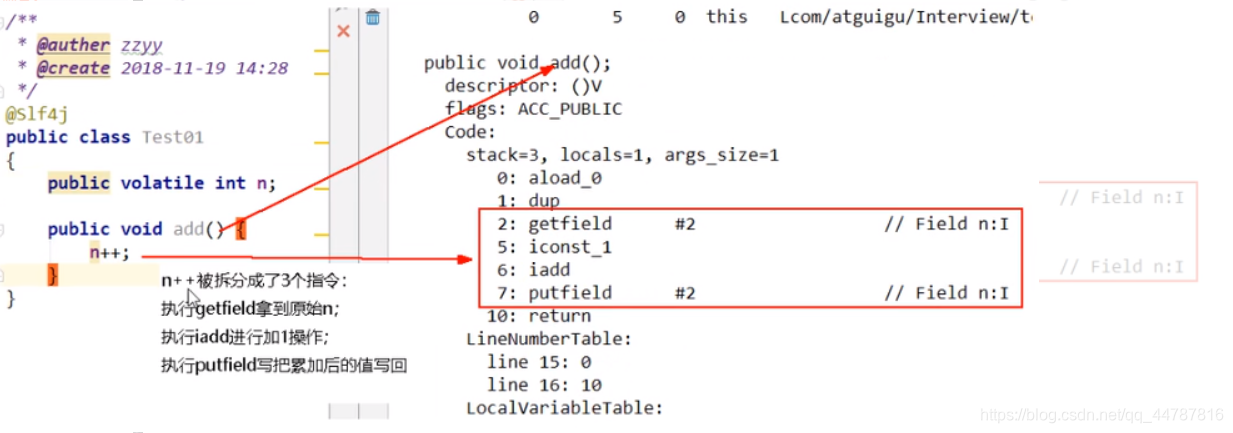
假设我们没有加 synchronized那么第一步就可能存在着,三个线程同时通过getfield命令,拿到主存中的 n值,然后三个线程,各自在自己的工作内存中进行加1操作,但他们并发进行 iadd 命令的时候,因为只能一个进行写,所以其它操作会被挂起,假设1线程,先进行了写操作,在写完后,volatile的可见性,应该需要告诉其它两个线程,主内存的值已经被修改了,**但是因为太快了,其它两个线程,陆续执行 iadd命令,进行写入操作,这就造成了其他线程没有接受到主内存n的改变,从而覆盖了原来的值,出现写丢失,**这样也就让最终的结果少于20000。
可加synchronized解决,但它是重量级同步机制,性能上有所顾虑。
如何不加synchronized解决number++在多线程下是非线程安全的问题?使用AtomicInteger。
结果:
计算机在执行程序时,为了提高性能,编译器和处理器的常常会对指令做重排,一般分以下3种:

单线程环境里面确保程序最终执行结果和代码顺序执行的结果一致。
处理器在进行重排序时必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
重排案例1
可重排序列:
1234
2134
1324
问题:请问语句4可以重排后变成第一个条吗?答:不能。
重排案例2
int a,b,x,y = 0
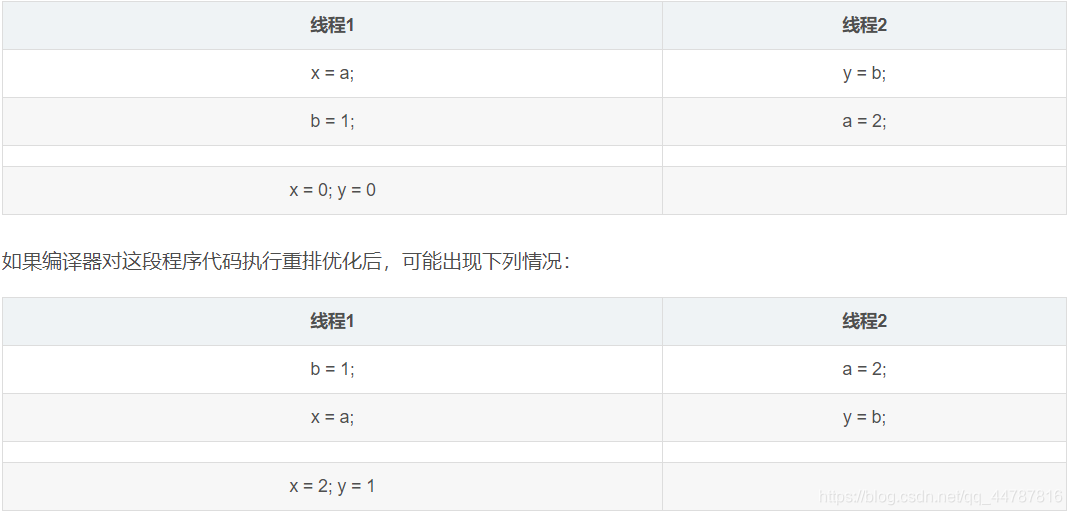
这也就说明在多线程环境下,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的。
以下程序在高并发的情况下,执行结果不一样
多线程环境中线程交替执行method01()和method02(),由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
禁止指令重排小总结
volatile实现禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象
先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
保证特定操作的执行顺序,保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)。
由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。内存屏障另外一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。
对volatile变量进行写操作时,会在写操作后加入一条store屏障指令,将工作内存中的共享变量值刷新回到主内存。
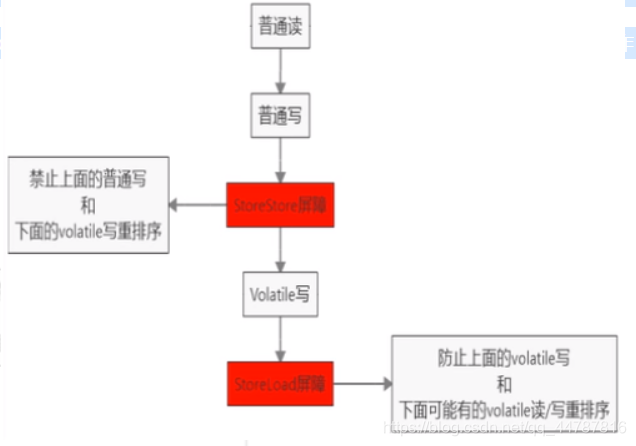
对Volatile变量进行读操作时,会在读操作前加入一条load屏障指令,从主内存中读取共享变量。
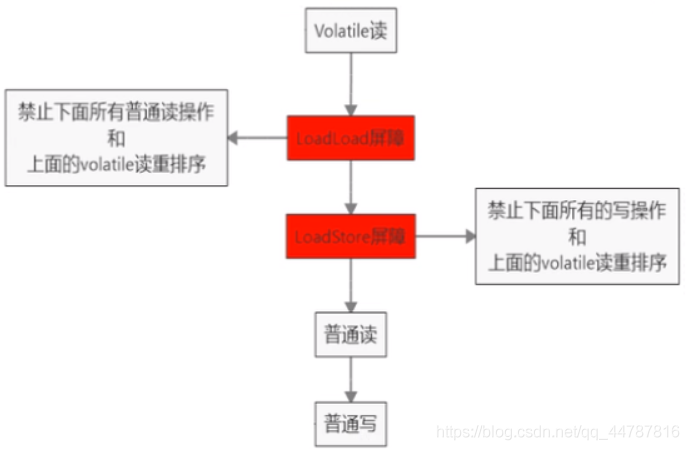
线性安全性获得保证
工作内存与主内存同步延迟现象导致的可见性问题 - 可以使用synchronized或volatile关键字解决,它们都可以使一个线程修改后的变量立即对其他线程可见。
对于指令重排导致的可见性问题和有序性问题 - 可以利用volatile关键字解决,因为volatile的另外一个作用就是禁止重排序优化。
多线程下,单例模式出现了并发安全问题
执行结果
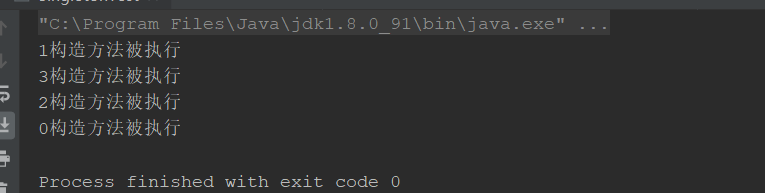
按理说,单例模式,应该只出现一个实例,但实际上出现了多个(多线程下)
解决方法:
方法一:使用synchronized
注意:这里采用了dcl双端检锁机制,保证并发的同时,保证效率
方法二: synchronized+ volatile
为什么要用volatile
我们看看 创建对象的过程,在并发环境下,是否会有问题
instance = new SingletonTest();可以分为以下3步完成(伪代码):
步骤2和步骤3不存在数据依赖关系,而且无论重排前还是重排后程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
但是指令重排只会保证串行语义的执行的一致性(单线程),但并不会关心多线程间的语义一致性。
在多线程情况下,可能没有实例化完成, 对象引用就指向了对应地址。对象!=null,但是内部没有数据,调用对应方法时,得不到对应结果。因此我们要禁止指令重排
Compare And Swap 比较并交换。CAS是一个cpu原语,该原子性操作不可被中断。
CAS的全称为Compare-And-Swap,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。(原子性)

下面我们举一个例子来演示CAS原理
atomiclnteger.getAndIncrement();



相关参数介绍
1 Unsafe
Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存。
Unsafe类中的方法主要是直接调用操作系统底层资源执行相应任务。
2 变量valueOffset
表示该变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的。
3 变量value
用volatile修饰,保证了多线程之间的内存可见性。
UnSafe.getAndAddInt()源码解释:
var1 AtomicInteger对象本身。
var2 该对象值得引用地址。
var4 需要变动的数量。
var5是用过var1,var2找出的主内存中真实的值。
用该对象当前的值与var5比较:
如果相同,更新var5+var4并且返回true,
如果不同,继续取值然后再比较,直到更新完成。(非常占用cpu)
举例:
假设线程A和线程B两个线程同时执行getAndAddInt操作(分别跑在不同CPU上) :
Atomiclnteger里面的value原始值为3,即主内存中Atomiclnteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存。
线程A通过getIntVolatile(var1, var2)拿到value值3,这时线程A被挂起。
线程B也通过getintVolatile(var1, var2)方法获取到value值3,此时刚好线程B没有被挂起并执行**compareAndSwapInt方法(CAS原语)**比较内存值也为3,成功修改内存值为4,线程B打完收工,一切OK。
这时线程A恢复,执行compareAndSwapInt方法比较,发现自己手里的值数字3和主内存的值数字4不一致,说明该值己经被其它线程抢先一步修改过了,那A线程本次修改失败,只能重新读取重新来一遍了。
线程A重新获取value值,因为变量value被volatile修饰,所以其它线程对它的修改,线程A总是能够看到,线程A继续执行compareAndSwaplnt进行比较替换,直到成功。
底层汇编
Unsafe类中的compareAndSwapInt,是一个本地方法,该方法的实现位于unsafe.cpp中。
1、占用过多CPU(循环取值比较)
当我们的预期值,与valueOffSet实际指向的值不同时,进行do-while循环,直到 预期值和内存中实际值 相同
2、CAS只能对一个变量进行原子性操作,而synchronized可以对一段代码进行锁操作
3、CAS存在ABA问题
存在两个线程t1,t2,同时访问共享变量A,将共享变量拷贝到线程自己的工作空间。由于t2处理速度快,可能直接修改A为B,再修改B为A。此时,如果t1要修改变量A,对变量A进行compareAndSwap。发现是A没变,直接修改。但是A其实已经被动过,A-B-A的过程可以发生很多事,A已经不再是原来那个单纯的A了
存在两个线程t1,t2,同时访问共享变量A,将共享变量拷贝到线程自己的工作空间。由于t2处理速度快,可能直接修改A为B,再修改B为A。此时,如果t1要修改变量A,对变量A进行compareAndSwap。发现是A没变,直接修改。但是A其实已经被动过,A-B-A的过程可以发生很多事,A已经不再是原来那个单纯的A了
之前我们了解过AtomicInteger是对Integer类型的共享变量,要保证数据一致性(原子性)问题时,采取的方案。
如果说我们需要将引用类型作为共享变量,保证原子性。可以使用AtomicReference。
结果:
怎么证明呢?
运行结果:


两个示例都抛出了并发修改异常。第二个示例foreach 会产生一个iterator进行迭代。
解决方法
1、synchronized
2、Reentrantlock
3、collections
看对应api即可
4、copyOnWriteAraaylist
CopyOnWriteArrayList遵循的是读写分离的思想。读取数据的时候,可以直接读取。但是写数据在多线程环境下,可能出现线程安全问题。
我们可以看下对应源码
add()
步骤
1、add对象时,获取可重入锁,只有线程获取到该锁,才能进行写操作
2、获取原对象数组,通过Arrays拷贝生成一个原数组的副本。将add的对象放入数组末尾,将原数组引用指向该进行了写操作的数组副本(这一部分保证原子性)
3、操作完后释放锁,其它线程可访问该方法进行写操作
get()
可以看到get方法并没有加锁,因此线程无需互斥访问get方法,提高了并发处理速度
hashMap底层由哈希表构成。 在jdk1.8中 hashMap由数组+链表+红黑树构成

在介绍HashMap之前,有必要知道
1、什么hash
Hash,一般翻译为“散列”,也有直接音译为“哈希”的,这就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值(哈希值);这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所有散列函数都有如下一个基本特性:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同。
2、什么是hashCode
我们以String为例
上面的计算将字符串的每一个字符+ hash*31然后相加得到新的,以此类推返回最终的hash值。
3、为什么要用31相乘
在名著 《Effective Java》第 42 页就有对 hashCode 为什么采用 31 做了说明:
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5) - i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
这个问题在 SO 上也有讨论: https://stackoverflow.com/questions/299304/why-does-javas-hashcode-in-string-use-31-as-a-multiplier)
可以看到,使用 31 最主要的还是为了性能。当然用 63 也可以。但是 63 的溢出风险就更大了。那么15 呢?仔细想想也可以。
在《Effective Java》也说道:编写这种散列函数是个研究课题,最好留给数学家和理论方面的计算机科学家来完成。我们此次最重要的是知道了为什么使用31。
我们以hashMap中的put方法为例,看看源码
1、当我们put一个k-v进来的时候,首先对key进行hash算法
可以看到key为null时,hash值为0,这就是为什么hashMap可以运行key为null。接下来,获取key的hashCode 与 hashcode右位移16位进行异或运算,返回hash值
2、判断数组(bucket数组)存不存在,大小是不是为0。如果没有数组,或者数组长度为0,进行resize()扩容。
数组默认大小16,负载因子0.75,阈值12(capacity*loadFactory)


3、通过(n-1)& hash 获取数组下标,取出对应位置的值。如果为null,可以放入数组。如果不为null,即hash冲突,通过equals比较key是否相等。如果相等则替换,不相等放入链表尾部。如果链表个数大于8,转红黑树
放入数组
不相等放入链表尾部。如果链表个数大于8,转红黑树

4、如果当前kv个数大于阈值,进行扩容
注意: modCount为结构上的修改次数
hash算法的大致过程:
1:由键key得出hashCode
2:由hashCode算出hash值,
3:由hash算出于数组中的下标
如下图所示:

1-我们知道无论是键还是值,都应该是一个对象,不同的对象具有不同的存储地址,hashCode得到的哈希值就是根据对象的地址转化而来的。
2:在hashmap中,对hashcode方法进行了重写,重写的时候用到了hash算法,即把hashcode的高16位与低16位进行异或运算,得到hash值。
3:把hash值与数组长度减一进行“与”运算得到下标。(这里需要注意的是,因为数组的长度始终是2的次方幂,这里的与运算,就相当于给length-1取模运算)
公平锁―是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后中请的线程比先中请的线程优先获取锁。在高并发的情况下,有可能会造成优先级反转或者饥饿现象
并发包中ReentrantLock的创建可以指定构造函数的boolean类型来得到公平锁或非公平锁,默认是非公平锁。
The constructor for this class accepts an optional fairness parameter. When set true, under contention, locks favor granting access to the longest-waiting thread. Otherwise this lock does not guarantee any particular access order. Programs using fair locks accessed by many threads may display lower overall throughput (i.e., are slower; often much slower) than those using the default setting, but have smaller variances in times to obtain locks and guarantee lack of starvation.
Note however, that fairness of locks does not guarantee fairness of thread scheduling. Thus, one of many threads using a fair lock may obtain it multiple times in succession while other active threads are not progressing and not currently holding the lock. Also note that the untimed tryLock() method does not honor the fairness setting. It will succeed if the lock is available even if other threads are waiting.
此类的构造函数接受可选的公平性参数。当设置为true时,在争用下,锁有利于向等待时间最长的线程授予访问权限。否则,此锁不保证任何特定的访问顺序。与使用默认设置的程序相比,使用由许多线程访问的公平锁的程序可能显示出较低的总体吞吐量(即,较慢;通常要慢得多),但是在获得锁和保证没有饥饿的时间上差异较小。
但是请注意,锁的公平性并不能保证线程调度的公平性。因此,使用公平锁的多个线程中的一个线程可以连续多次获得公平锁,而其他活动线程则没有进行并且当前没有持有该锁。还要注意,不计时的 tryLock()方法不支持公平性设置。如果锁可用,即使其他线程正在等待,它也会成功。
两者区别
关于两者区别:
公平锁
Threads acquire a fair lock in the order in which they requested it.
公平锁就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
非公平锁
a nonfair lock permits barging: threads requesting a lock can jump ahead of the queue of waiting threads if the lockhappens to be available when it is requested.
非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。
非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁
值得注意的是:jvm对线程的调度策略是抢占式的,优先级越高的线程,可能越会获取cpu的处理权
可重入锁(也叫做递归锁)
指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁(也即线程对于内存锁代码,不需要再次争抢锁)。
也即是说,线程可以进入任何一个它已经拥有的锁所同步着的代码块。
ReentrantLock/synchronized就是一个典型的可重入锁。
可重入锁最大的作用是避免死锁。
synchronized可重入锁
输出结果
ReentrantLock可重入锁
输出结果
自旋锁(Spin Lock)
是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU (以循环方式消耗cpu的代价,不让线程堵塞(挂起))
unsafe中的getAndAddInt就是一个良好示例
提到了互斥同步对性能最大的影响阻塞的实现,挂起线程和恢复线程的操作都需要转入内核态完成,这些操作给系统的并发性能带来了很大的压力。同时,虚拟机的开发团队也注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程 “稍等一下”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
《深入理解JVM.2nd》Page 398
为什么要使用自旋锁,就是多个线程对同一变量进行访问,为了线程安全加锁,但是由于线程使用共享变量很短一段时间,挂起线程进入堵塞状态,然后回复,消耗大。因此采用循环访问锁的方式,获取锁。
独占锁:指该锁一次只能被一个线程所持有。对ReentrantLock和Synchronized而言都是独占锁
共享锁:指该锁可被多个线程所持有。
多个线程同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行。但是,如果有一个线程想去写共享资源来,就不应该再有其它线程可以对该资源进行读或写。
对ReentrantReadWriteLock其读锁是共享锁,其写锁是独占锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读,写写的过程是互斥的。
读写锁详解
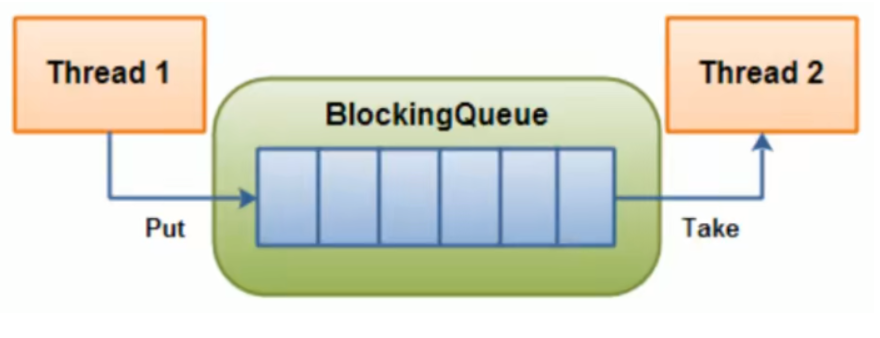
堵塞队列本质就是队列,底层数据结构 通常是由数组,或者链表构成。实现FIFO思想
当阻塞队列是空时,从队列中获取元素的操作将会被阻塞。
当阻塞队列是满时,往队列里添加元素的操作将会被阻塞。
注意:bolckingQueue是在多线程环境下提供的线程安全的队列
与ArrayList区别
1、ArrayList线程不安全,blockingQueue线程安全
2、ArrayList可以扩容,blockingQueue队列不能
1、我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,BlockingQueue都给你一手包办了
2、如果有很多任务要处理,我们当前处理不了,总不能不处理。我们可以延迟处理,总比不处理要好
1、生产者消费者模式
传统版(synchronized, wait, notify)
阻塞队列版(lock, await, signal)
2、线程池
3、消息中间件
blockingQueue实现类
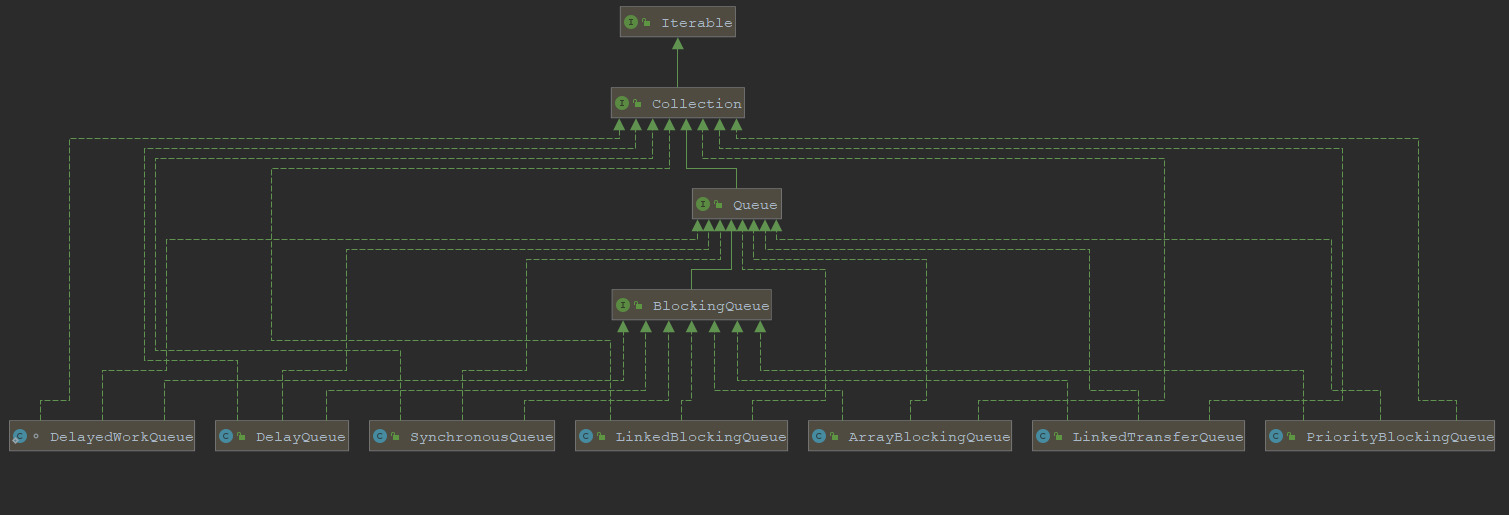
ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为Integer.MAX_VALUE)阻塞队列。
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
DelayQueue:使用优先级队列实现延迟无界阻塞队列。
SynchronousQueue:不存储元素的阻塞队列(生产一个消费一个)。
LinkedTransferQueue:由链表结构绒成的无界阻塞队列。
LinkedBlockingDeque:由链表结构组成的双向阻塞队列。
BlockingQueue核心方法组


offer和poll组
结果:
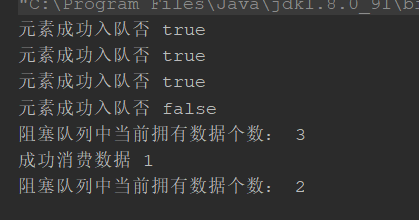
阻塞队列中只能存放指定个数的数据,如果使用offer(),将数据放入队列,当前队列已满,消费线程没有来得及消费,那么offer放入数据会失败
超时的 offer和poll组 与上面代码类似,只不过加了时间限制
put和take组
结果:
使用put将数据消息进入队列,如果队列满了,并且没有消费者线程进行消费,那么一直会堵塞线程,只要队列不为满时,将元素放入才不会堵塞线程
SynchronousQueue没有容量。
与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。
每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。
放一个拿一个,存在一个就不能放了哦
1、synchronized控制的
2、lock(ReentrantLock)
两者运行结果:
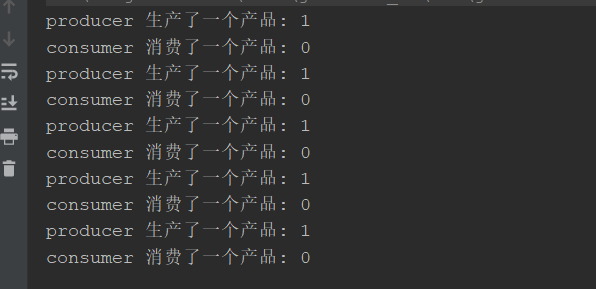
存在多个线程并发争抢一个资源。以生产者消费者为例:
我们任务要求,只能生产一个产品消费一个产品。两个生产者生产,两个消费者消费。
当生产者生产完一个产品时,要唤醒等待的线程(notify是随机唤醒)。注意此时有两个消费者线程,一个生产者线程等待。如果cpu的调度权被等待的生产者获取到了,此时生产者在 wait()方法处 会直接往下执行,实际上就生产了两个产品。同理消费者也可能同时消费两个产品
根源在于:换性的线程是直接往下执行的并没有判断是否满足对应条件

产生虚假唤醒的源码
可能的结果
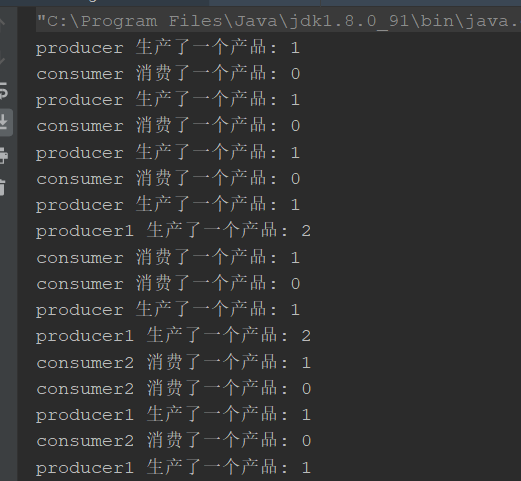
解决:
if该while即可,唤醒的同时,进行再次判断

总结具有 await/wait方法时,需要使用while
1、synchronized属于JVM层面,属于java的关键字
monitorenter(底层是通过monitor对象来完成,其实wait/notify等方法也依赖于monitor对象 只能在同步块或者方法中才能调用 wait/ notify等方法)
Lock是具体类(java.util.concurrent.locks.Lock)是api层面的锁
2、使用方法:
synchronized:不需要用户去手动释放锁,当synchronized代码执行后,系统会自动让线程释放对锁的占用。
ReentrantLock:则需要用户去手动释放锁,若没有主动释放锁,就有可能出现死锁的现象,需要lock() 和 unlock() 配置try catch语句来完成
3、等待是否中断
synchronized:不可中断,除非抛出异常或者正常运行完成。
ReentrantLock:可中断,可以设置超时方法
设置超时方法,trylock(long timeout, TimeUnit unit)
lockInterrupible() 放代码块中,调用interrupt() 方法可以中断
4、加锁是否公平
synchronized:非公平锁
ReentrantLock:默认非公平锁,构造函数可以传递boolean值,true为公平锁,false为非公平锁
5、锁绑定多个条件Condition
synchronized:没有,要么随机,要么全部唤醒
ReentrantLock:用来实现分组唤醒需要唤醒的线程,可以精确唤醒,而不是像synchronized那样,要么随机,要么全部唤醒
任务:
多线程之间按顺序调用,实现 A-> B -> C 三个线程启动,要求如下:
AA打印5次,BB打印10次,CC打印15次
执行结果
注意: Condition在哪个线程,表示是哪个线程的条件,其它线程可以使用其线程的对应condition精准控制线程调用
相比于runnable接口而言,callable可以抛出异常,并且返回返回值


callable接口基本使用
缺点:
我们知道创建线程需要时间和空间。如果使用一次就不在使用,会等待 young GC 回收。当有大量的异步任务时,创建大量线程对象,消耗了时间和堆空间,会导致eden区 更早触发young gc,进一步降低效率。
优点:
降低资源消耗。通过重复利用己创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
1、继承Thread
2、实现Runnable
3、实现Callable
4、使用线程池
我们以Executors为例
Executors为线程工具类,使用时可以便捷的创建线程。
1、Executors.newFixedThreadPool(3);

固定大小的线程池
2、Executors.newSingleThreadExecutor();
单一线程的线程池
3、Executors.newCachedThreadPool();
可缓存线程的线程池
线程池七大参数

1、corePoolSize 核心线程数(常驻线程)
2、maximumPoolSize 最大线程数 (线程池容纳的最大线程,当堵塞队列和常驻线程都没有空间时,会开启最大线程数-核心线程数得到的线程)
3、keepAliveTime 最大线程数-核心线程数得到的线程 存活的时间
4、TimeUnit 时间单元
5、BlockingQueue 存放线程执行任务的堵塞队列(该队列是线程安全的,当线程池中线程没时间处理任务时,任务进入堵塞队列)
6、ThreadFactory 生产线程的工厂
7、RejectedExecutionHandler 拒绝执行的处理器策略,当maximumPoolSize对应的线程都在执行任务,堵塞队列也满了,对后来的线程的拒绝执行的处理策略


Executors创建的线程,底层都是通过ThreadPoolExecutor创建的,并且使用的是LinkedBlockingQueue队列,默认最大Integer.MAX_VALUE。这意味这,除非没有内存了,不然队列永远满不了。在高并发下,内存中会囤积大量的异步任务,容易发生OOM,线程的执行效率也会变低。

等待队列也已经排满了,再也塞不下新任务了同时,线程池中的max线程也达到了,无法继续为新任务服务。
这时候我们就需要拒绝策略机制合理的处理这个问题。
JDK拒绝策略:
1、AbortPolicy(默认):直接抛出 RejectedExecutionException异常阻止系统正常运知。
2、CallerRunsPolicy:"调用者运行"一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
3、DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务。
4、DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种方案。
注意:开发中常见的应该是scheduledThreadPoolExecutor+ timerTask
核心线程 和 blockingQueue 已满会创建 剩下的线程执行。
如果max线程 和 blockingQueue 已满会 还有任务要处理,该任务直接丢弃
CPU密集型
CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),
而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就那些。
CPU密集型任务配置尽可能少的线程数量:
一般公式:(CPU核数+1)个线程的线程池
例如:8核+8 = 16
lO密集型
由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如CPU核数 * 2。
IO密集型,即该任务需要大量的IO,即大量的阻塞。
在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。
所以在IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
IO密集型时,大部分线程都阻塞,故需要多配置线程数:
参考公式:CPU核数/ (1-阻塞系数)
阻塞系数在0.8~0.9之间
比如8核CPU:8/(1-0.9)=80个线程数

简单点来说,两个或两个以上的线程情景下,线程A持有锁资源A,但是还想要资源B,于是请求B锁,线程B持有锁资源B,但是还想要资源A,于是请求A锁。两者互不释放锁,又想获得对方资源。
死锁条件
1、请求保持
2、资源不可剥夺
3、资源互斥访问
4、循环等待
实例
结果:

破环死锁,只需要破坏四个条件之一即可
以演示死锁为例
jps -l 查看java中进程列表jstack 查看对应进程的执行栈

注意:方法区的实现是MetaSpace,JVM中方法区和堆是共享的,每一个线程的自己独立的执行栈,pc计数器,本地方法栈均为线程私有


1、创建的对象都会放入heap中的Eden区
2、当Eden区满时,会开启youngGC,存活对象放入from区
3、下次扫描时,就会扫描Eden区和from区,将存活的对象放入To区,From区和To区进行交换(复制交换)
4、当对象经过15次交换后,将对象放入oldGen(full GC 主要是回收oldGen对象)
1、引用计数

2、复制交换

3、标记-清除

4、标记-清除-压缩

优点:无内存碎片
缺点:三次扫描,耗时大
1、GC root原理
GC root原理:通过对枚举GCroot对象做引用可达性分析,即从GC root对象开始,向下搜索,形成的路径称之为 引用链。如果一个对象到GC roots对象没有任何引用,没有形成引用链,那么该对象等待GC回收。

2、GC root对象是什么?
Java中可以作为GC Roots的对象
1、虚拟机栈(javaStack)(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
2、方法区中的类静态属性引用的对象。
3、方法区中常量引用的对象。
4、本地方法栈中JNI(Native方法)引用的对象。
1、标准参数
version java -versionhelp
2、X参数
Xint:解释执行Xcomp:第一次使用就编译成本地代码Xmixed:混合模式
3、XX参数
xx参数分为boolean类型参数 和 kv类型参数
3.1、boolean类型参数参数
-XX:+ 或者 - 某个属性值(+表示开启,-表示关闭)
是否打印GC收集细节
-XX:-PrintGCDetails-XX:+PrintGCDetails
是否使用串行垃圾回收器
-XX:-UseSerialGC-XX:+UserSerialGC
3.2、KV类型参数参数
-XX:InitialHeapSize=xxxx-XX:maxHeapSize=xxx
实例:
查看一个正在运行的java应用,jvm配置如何?
jps -l 查看正在运行中的java程。jinfo -flag PrintGCDetails 进程pid 查看它的某个jvm参数(如PrintGCDetails )是否开启。jinfo -flags 进程pid 查看它的所有jvm参数
-XX:InitialHeapSize=132120576 JVM最初堆内存大小(默认是物理内存的64分之一)
-XX:MaxHeapSize=2097152000 JVM最大堆大小(默认是物理内存的4分之一)
-XX:+PrintGCDetails 打印输出GC回收信息


-XX:+PrintFlagsInitial
使用方式:java -XX:+PrintFlagsInitial 也可以将XX参数配置在VM option中启动引用查看
数据过多,有需要自己查看
uintx MetaspaceSize = 21810376 {pd product}
元空间大小为21M左右
-XX:+PrintFlagsFinal
使用方式:java -XX:+PrintFlagsFinal 可以将XX参数配置在VM option中启动引用查看

-XX:ThreadStackSize 配置线程栈大小
-Xmn:设置年轻代大小 (这是简写形式,我个人喜欢用全称,好记)
-XX:MetaspaceSize 设置元空间大小
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。
java中的引用类型分别是强引用,SoftReference,WeakReference,PhantomReference。

我们平常中产生的对象绝大部分是强引用类型,下来来分别介绍。
特点
当内存不足,JVM开始通过垃圾回收器进行垃圾回收,对于强引用的对象,就算是出现了OOM也不会对该对象进行回收,因为存在引用指向这它,我们平常创建的对象都是强引用对象。要将强引用对象回收,只需引用指向null即可,等待gc回收
这里我们启动程序的时候,为了出现内存不足现象,使用了jvm -XX参数。只需vm option配置即可
-XX:InitialHeapSize=10m -XX:MaxHeapSize=10m -XX:+PrintGCDetails
特点
1、当内存充足时,只要软引用对象还有引用指向,就不会被gc回收
2、当内存不充足时,不管软引用对象有没有被指向,都会被回收
结果:
特点
只要gc就会回收弱引用对象,不管弱引用对象,有没有引用指向
结果:
需要对图片进行大量缓存
1、如果每次读取图片都从硬盘读取则会严重影响性能
2、如果一次性全部加载到内存中,又可能造成内存溢出
此时使用软引用可以解决这个问题。
设计思路:使用HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占的空间,从而有效地避免了OOM的问题
WeakHashMap存储虚引用对象
一旦回收,map为空
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收,它不能单独使用也不能通过它访问对象,虚引用必须和引用队列(ReferenceQueue)联合使用。
虚引用的主要作用是跟踪对象被垃圾回收的状态。仅仅是提供了一种确保对象被finalize以后,做某些事情的机制。
StackoverFlowError
java.lang.StackOverflowError (线程执行栈,栈溢出)
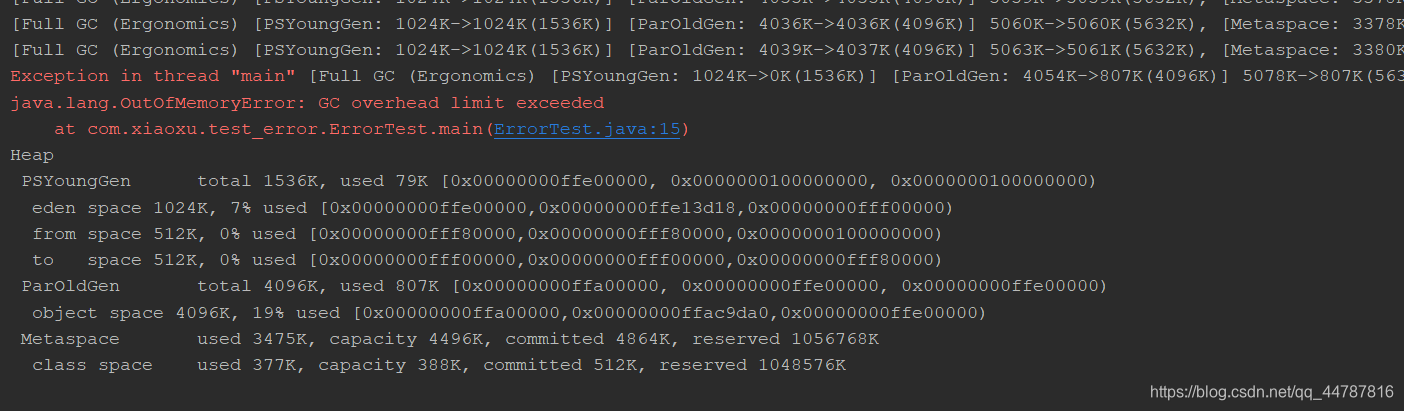
OutofMemoryError
java.lang.OutOfMemoryError:java heap space (堆空间不足)java.lang.OutOfMemoryError:GC overhead limit exceeded (gc垃圾收集器负载过重,就是gc也回收不了垃圾)java.lang.OutOfMemoryError:Direct buffer memory (jvm堆内存之外的物理内存不足)java.lang.OutOfMemoryError:unable to create new native thread (线程的创建数量过多导致,内存不足)java.lang.OutOfMemoryError:Metaspace (元空间内存不足)
结果:
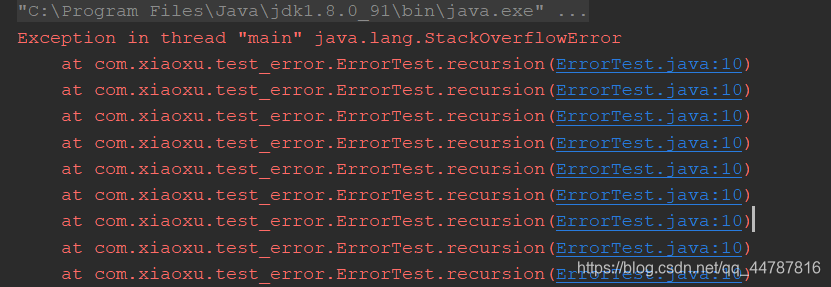
线程的栈大小默认是1024kb,一旦超出该大小就会产生stackOverFlow
配置java程序启动jvm参数
-XX:+PrintGCDetails -XX:InitialHeapSize=5m -XX:MaxHeapSize=5m
配置java程序启动jvm参数
-XX:+PrintGCDetails -XX:InitialHeapSize=5m -XX:MaxHeapSize=5m
产生此次错误,主要是jvm堆中存在大量对量被引用,gc一直无法回收垃圾,导致gc负载过重
值得注意的是:如果是创建字符串常量的话,放在常量池中,常量池位于方法区,对应实现是MetaSpace。对象是放在物理jvm之外的物理内存中
配置程序启动时jvm参数
-XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
导致原因:
写NIO程序经常使用ByteBuffer来读取或者写入数据,这是一种基于通道(Channel)与缓冲区(Buffer)的IO方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避兔了在Java堆和Native堆中来回复制数据。
ByteBuffer.allocate(capability) 第一种方式是分配VM堆内存,属于GC管辖范围,由于需要拷贝所以速度相对较慢。
ByteBuffer.allocateDirect(capability) 第二种方式是分配OS本地内存,不属于GC管辖范围,由于不需要内存拷贝所以速度相对较快。
但如果不断分配本地内存,堆内存很少使用,那么JV就不需要执行GC,DirectByteBuffer对象们就不会被回收,这时候堆内存充足,但本地内存可能已经使用光了,再次尝试分配本地内存就会出现OutOfMemoryError,那程序就直接崩溃了。
jvm启动时附带的参数
-XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
结果
导致原因:
应用创建了太多线程,一个应用进程创建多个线程,超过系统承载极限
服务器并不允许你的应用程序创建这么多线程**,linux系统默认运行单个进程可以创建的线程为1024个**,如果应用创建超过这个数量,就会报 java.lang.OutOfMemoryError:unable to create new native thread
配置java程序启动jvm参数
-XX:+PrintGCDetails -XX:InitialHeapSize=5m -XX:MaxHeapSize=5m
注意:可能会导致死机
元空间主要是方法区的实现,存放常量池,静态变量,类相关信息等
默认的元空间大小为21M左右
通过jvm参数 -XX:PrintFlagsFinal 或者 jinfo -flag MetaspaceSize 查看


一旦元空间满了,要注意元空间中存放的信息
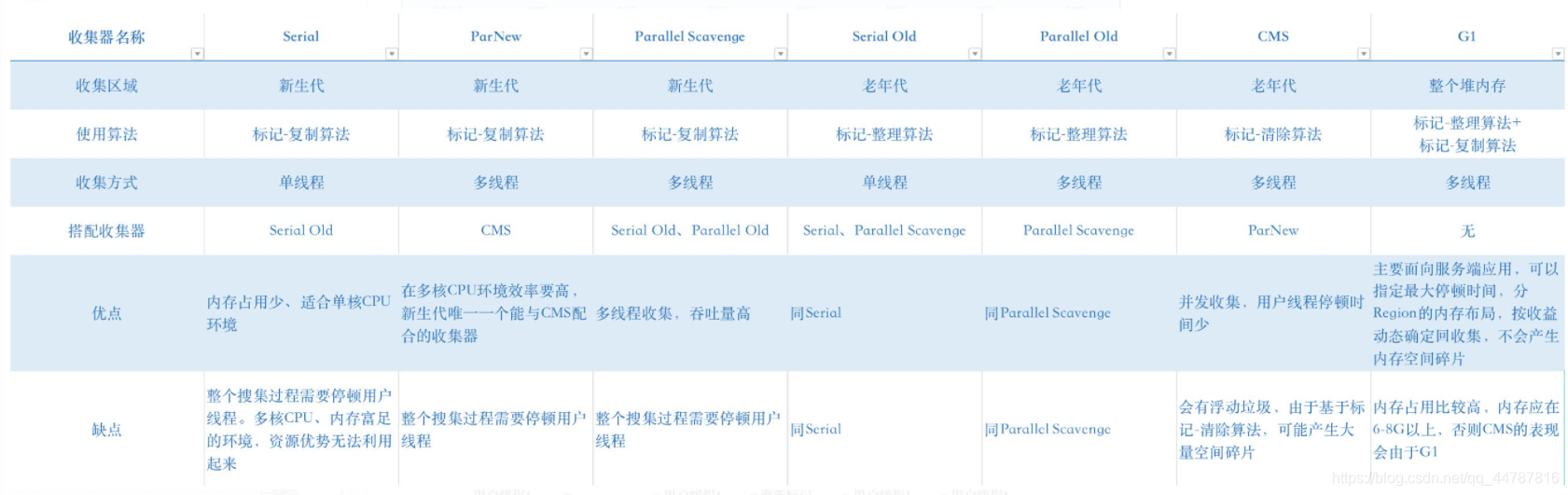
1、serial 串行垃圾收集器,采用单线程收集垃圾
2、parallel 并行垃圾收集器,采用多线程收集垃圾
3、CMS(concurrentMarkSweep)并发标记收集 垃圾收集器,串行和并行同在,是前两种垃圾收集器的优化,较短时间进行STW(stop the world),保证较快的响应速度。
4、G1 新一代垃圾收集器,采用的region分区
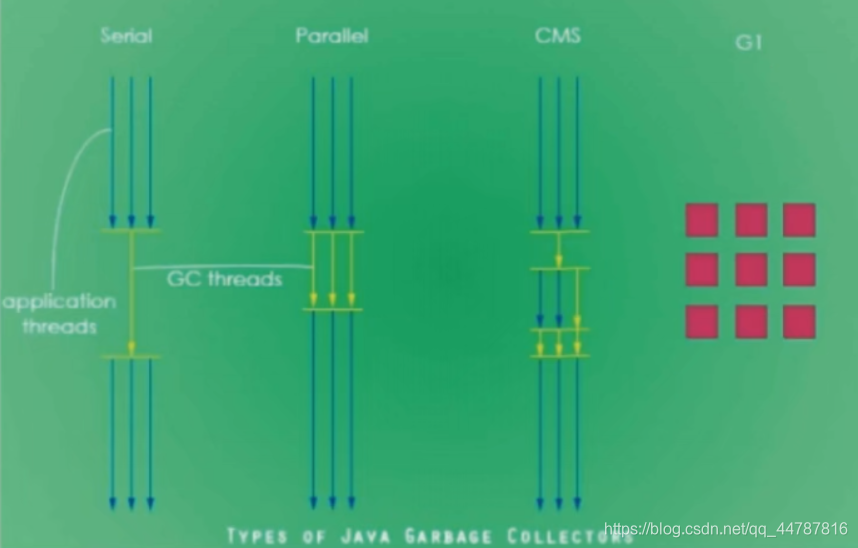
java8中默认使用的是ParallelGC
年轻代GC
1、UserSerialGC:串行垃圾收集器
2、UserParallelGC:并行垃圾收集器
3、UseParNewGC:年轻代的并行垃圾回收器
新生代中采用的垃圾收集算法 基本都是 标记复制算法/复制拷贝
老年代GC
1、UserSerialOldGC:串行老年代垃圾收集器(已经被移除)
2、UseParallelOldGC:老年代的并行垃圾回收器
3、UseConcMarkSweepGC:(CMS)并发标记清除
老年代中采用的来及收集算法 基本都是 标记清除,标记清除压缩
youngGen 和 oldGen 使用的GC
UseG1GC:G1垃圾收集器
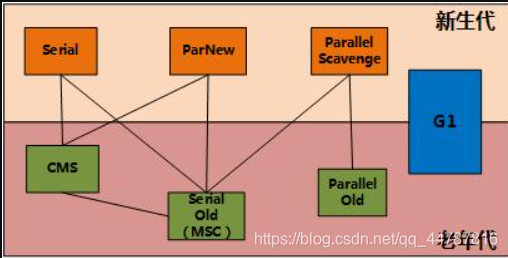
下面两个图很重要
注意:下面图中指的是可以这样搭配,但是jvm中会有默认搭配机制
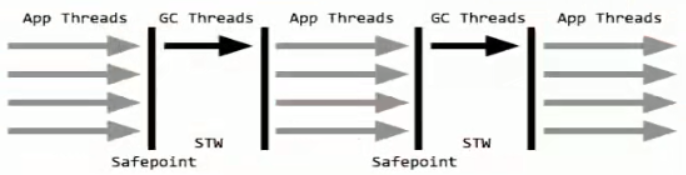
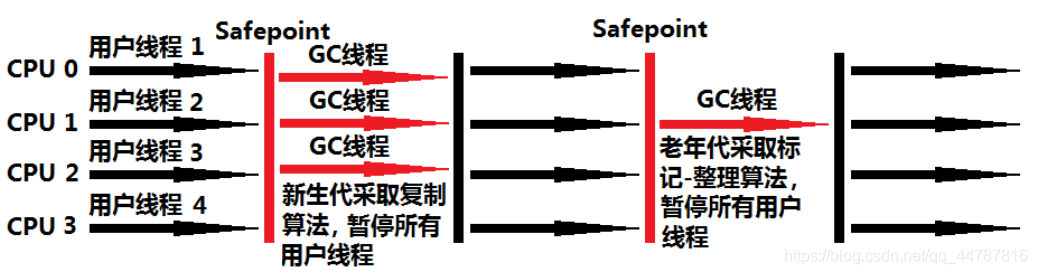
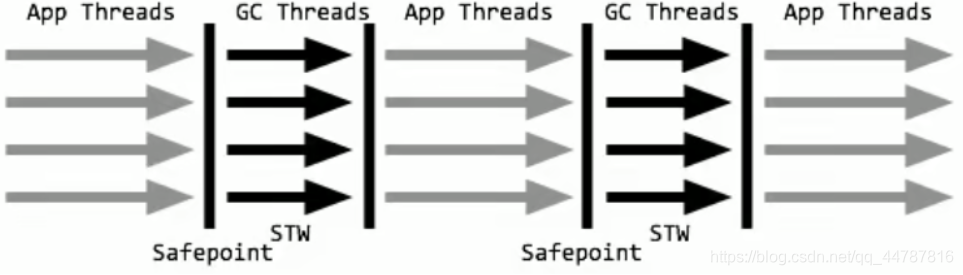
一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程(STW)直到它收集结束。
新生代老年代都是单线程的垃圾回收
STW: Stop The World
串行收集器是最古老,最稳定以及效率高的收集器,只使用一个线程去回收但其在进行垃圾收集过程中可能会产生较长的停顿(Stop-The-World”状态)。虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限定单个CPU环境来说,没有线程交互的开销可以获得最高的单线程垃圾收集效率,因此Serial垃圾收集器依然是java虚拟机运行在Client模式下默认的新生代垃圾收集器。
如果让jvm使用Serial垃圾收集器
-XX:+UseSerialGC
实例:
jvm配置参数
-XX:+UseSerialGC -XX:+PrintGCDetails -XX:MaxHeapSize=5m -XX:InitialHeapSize=5m
paraNew是在新生代中的并行多线程垃圾收集器,老年代采用单线程垃圾收集器。
ParNew(Young区)+ Serial Old的收集器组合,新生代使用复制算法,老年代采用标记-整理算法
jvm参数配置
-XX:+UseParNewGC -XX:+PrintGCDetails -XX:MaxHeapSize=5m -XX:InitialHeapSize=5m
新生代和老年代都采用多线程的垃圾收集器
jvm参数配置
-XX:+UseParallelGC -XX:+PrintGCDetails -XX:MaxHeapSize=5m -XX:InitialHeapSize=5m
ParallelOld收集器是老年代采用的垃圾收集器,使用的算法是标记清除, 与之对应的新生代垃圾收集器ParallelScavenge
上文介绍过
即使我配置-XX:UseParallelOldGC,新生代默认也会配置成ParallelScavenge 注意这是默认的。新生代配置ParallelScavenge,老年代还是配置成这个
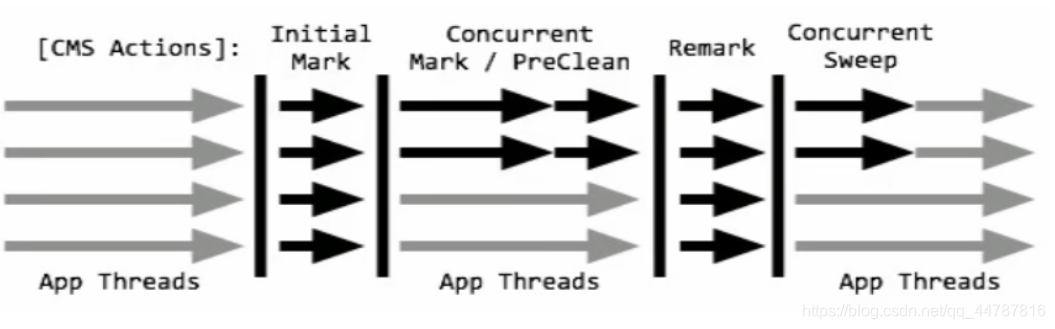
CMS收集器(Concurrent Mark Sweep:并发标记清除)是一种以获取最短回收停顿时间为目标的收集器。
适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短。
CMS非常适合地内存大、CPU核数多的服务器端应用,也是G1出现之前大型应用的首选收集器。
注意
新生代使用ParNew收集器,老年代会使用收集器SerialOldGC
使用jvm参数配置
-XX:+UseConcMarkSweepGC 新生代会自动使用ParNew
开启该参数后,使用ParNew(Young区用)+ CMS(Old区用)+ Serial Old的收集器组合,Serial Old将作为CMS出错的后备收集器。
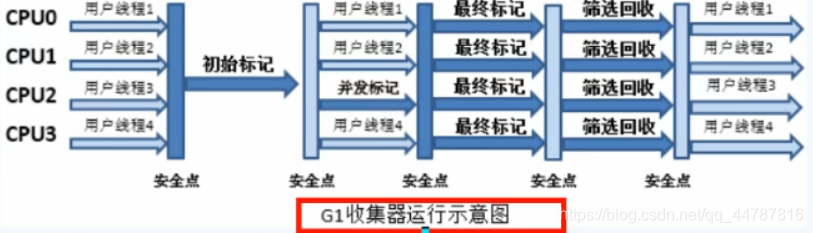
4步过程:
1、初始标记(CMS initial mark) - 只是标记一下GC Roots能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
2、并发标记(CMS concurrent mark)和用户线程一起 - 进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程。主要标记过程,标记全部对象。
3、重新标记(CMS remark)- 为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正。
4、并发清除(CMS concurrent sweep) - 清除GCRoots不可达对象,和用户线程一起工作,不需要暂停工作线程。基于标记结果,直接清理对象,由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看CMS 收集器的内存回收和用户线程是一起并发地执行。
优点:并发收集低停顿,响应速度快。
缺点:并发执行,对CPU资源压力大,采用的标记清除算法会导致大量碎片。
jvm参数配置
-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:MaxHeapSize=5m -XX:InitialHeapSize=5m
后面讲
单线程,标记整理算法,不再赘述
组合的选择
单CPU或者小内存,单机程序
-XX:+UseSerialGC
多CPU,需要最大的吞吐量,如后台计算型应用(java8默认)
-XX:+UseParallelGC(这两个相互激活)
-XX:+UseParallelOldGC
多CPU,追求低停顿时间,需要快速响应如互联网应用
-XX:+UseConcMarkSweepGC
-XX:+ParNewGC
G1 (Garbage-First)收集器,是一款面向服务端应用的收集器
特点:
G1能充分利用多CPU、多核环境硬件优势,尽量缩短STW。
G1整体上采用标记-整理算法,局部是通过复制算法,不会产生内存碎片。
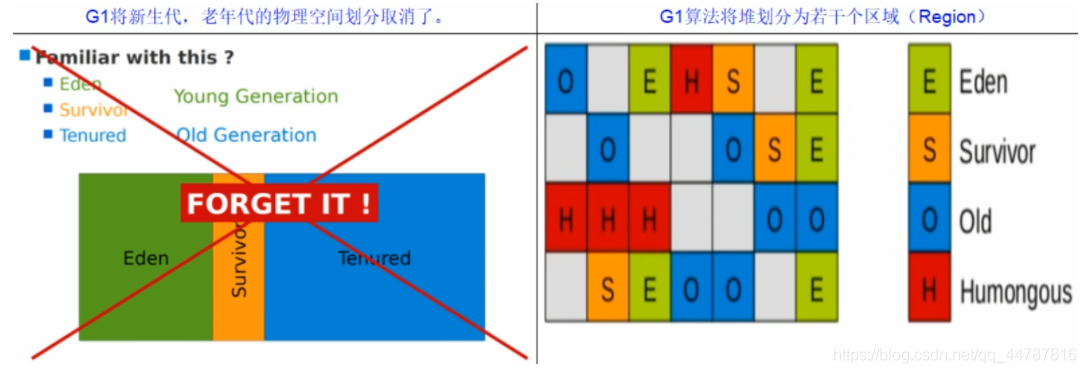
宏观上看G1之中不再区分年轻代和老年代。把内存划分成多个独立的子区域(Region),可以近似理解为一个围棋的棋盘。
G1收集器里面讲整个的内存区都混合在一起了,但其本身依然在小范围内要进行年轻代和老年代的区分,保留了新生代和老年代,但它们不再是物理隔离的,而是一部分Region的集合且不需要Region是连续的,也就是说依然会采用不同的GC方式来处理不同的区域。
G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换。
目的
G1收集器的设计目标是取代CMS收集器,它同CMS相比,在以下方面表现的更出色:
G1是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片。
G1的Stop The World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
CMS垃圾收集器虽然减少了暂停应用程序的运行时间,但是它还是存在着内存碎片问题。于是,为了去除内存碎片问题,同时又保留CMS垃圾收集器低暂停时间的优点,JAVA7发布了一个新的垃圾收集器-G1垃圾收集器。
G1是在2012年才在jdk1.7u4中可用。oracle官方计划在JDK9中将G1变成默认的垃圾收集器以替代CMS。它是一款面向服务端应用的收集器,主要应用在多CPU和大内存服务器环境下,极大的减少垃圾收集的停顿时间,全面提升服务器的性能,逐步替换java8以前的CMS收集器。
主要改变是Eden,Survivor和Tenured等内存区域不再是连续的了,而是变成了一个个大小一样的region ,每个region从1M到32M不等。一个region有可能属于Eden,Survivor或者Tenured内存区域。
回收步骤
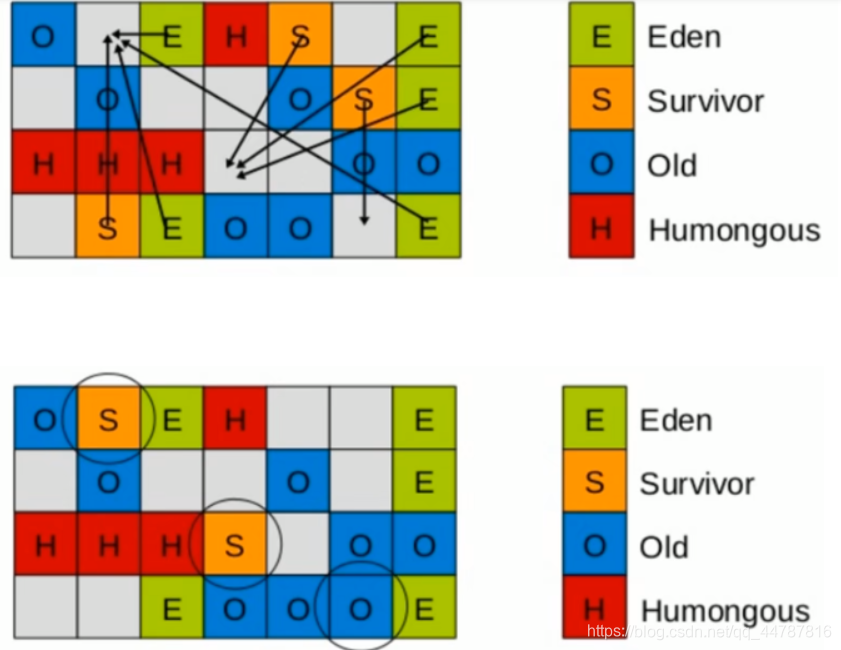
G1收集器下的Young GC
针对Eden区进行收集,Eden区耗尽后会被触发,主要是小区域收集+形成连续的内存块,避免内存碎片
Eden区的数据移动到Survivor区,假如出现Survivor区空间不够,Eden区数据会部会晋升到Old区。
Survivor区的数据移动到新的Survivor区,部会数据晋升到Old区。
最后Eden区收拾干净了,GC结束,用户的应用程序继续执行。
4步过程:
初始标记:只标记GC Roots能直接关联到的对象
并发标记:进行GC Roots Tracing的过程
最终标记:修正并发标记期间,因程序运行导致标记发生变化的那一部分对象
筛选回收:根据时间来进行价值最大化的回收
-XX:+UseG1GC
-XX:G1HeapRegionSize=n:设置的G1区域的大小。值是2的幂,范围是1MB到32MB。目标是根据最小的Java堆大小划分出约2048个区域。
-XX:MaxGCPauseMillis=n:最大GC停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间。
-XX:InitiatingHeapOccupancyPercent=n:堆占用了多少的时候就触发GC,默认为45。
-XX:ConcGCThreads=n:并发GC使用的线程数。
-XX:G1ReservePercent=n:设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险,默认值是10%。
开发人员仅仅需要声明以下参数即可:
三步归纳:开始G1+设置最大内存+设置最大停顿时间
-XX:+UseG1GC
-Xmx32g
-XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=n:最大GC停顿时间单位毫秒,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间
G1和CMS比较
G1不会产生内碎片
是可以精准控制停顿。该收集器是把整个堆(新生代、老年代)划分成多个固定大小的区域,每次根据允许停顿的时间去收集垃圾最多的区域。
java -server jvm的各种参数 -jar jar/war包名
用法
top [-d number] | top [-bnp]
-d:number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。
-b:以批次的方式执行top。
-n:与-b配合使用,表示需要进行几次top命令的输出结果
-p:指定特定的pid进程号进行观察
top命令使用详解

用法
vmstat

procs
r:运行和等待的CPU时间片的进程数,原则上1核的CPU的运行队列不要超过2,整个系统的运行队列不超过总核数的2倍,否则代表系统压力过大,我们看蘑菇博客测试服务器,能发现都超过了2,说明现在压力过大
b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等
cpu
us:用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序
sy:内核进程消耗的CPU时间百分比
us + sy 参考值为80%,如果us + sy 大于80%,说明可能存在CPU不足,从上面的图片可以看出,us + sy还没有超过百分80,因此说明蘑菇博客的CPU消耗不是很高
id:处于空闲的CPU百分比
wa:系统等待IO的CPU时间百分比
st:来自于一个虚拟机偷取的CPU时间比
用法
注意:默认是没有pidstat命令的,需要 安装一下

用法
经验值
应用程序可用内存l系统物理内存>70%内存充足
应用程序可用内存/系统物理内存<20%内存不足,需要增加内存
20%<应用程序可用内存/系统物理内存<70%内存基本够用


rkB/s每秒读取数据量kB;wkB/s每秒写入数据量kB;
svctm lO请求的平均服务时间,单位毫秒;
await l/O请求的平均等待时间,单位毫秒;值越小,性能越好;
util一秒中有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
rkB/s、wkB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
svctm的值与await的值很接近,表示几乎没有IO等待,磁盘性能好。
如果await的值远高于svctm的值,则表示IO队列等待太长,需要优化程序或更换更快磁盘。
1、先用top命令找出CPU占比最高的

2、ps -ef或者jps -l 进一步定位,定位进程
3、定位到具体线程或者代码
ps -mp 进程 -o THREAD,tid,time
-m 显示所有的线程
-p pid进程使用cpu的时间
-o 该参数后是用户自定义格式 要显示的内容

4、jstack 进程ID | grep tid -A60
查看对应进程中,对应线程的栈信息
watch:会持续收到该项目的动态
fork:复制其个项目到自己的Github仓库中
star,可以理解为点赞
clone,将项目下载至本地
follow,关注你感兴趣的作者,会收到他们的动态
关键词 in:name/description/readme
例如:springboot 存在于name,readme中的项目
springboot in:name,readme

关键字 stars: fork:
实例
springboot stars:>=2000 fork:>=200

awesome 项目/教程/案例
用来收集一系列较好的项目
awesome springboot

#L 主要是用来查看代码,进行高亮的
实例

location:hangzhou language:java
